Mastodon Integration
Well, damn it. Here I am procrastinating on my archviz project with a server side project. I am an infrastructure engineer at heart, so anything server related will always pull at me harder than any other project. So right after writing the Future Work section in my last post, I started looking more closely at Daniel's approach to using mastodon for comments. The part that scratched my server-side geek itch was his chicken-egg problem forcing the workflow:
- create post
- create toot
- update post with toot id
I just want to publish my post, have a matching toot automatically be generated and have the original post be able to discover the corresponding toot_id. I want to keep my blog static and don't really want to add this into the build pipeline, so what I need is a web service that will lazy publish the toot and return the toot_id for a given URL.
Design
I know, if you have a hammer... But this webservice does simplify the workflow by automating the mastodon posting and integrating it into the post. The service should have the following qualities:
- get invoked by visiting the page
- no manual
publishcall should be required
- no manual
- making a page publishable should be as simple as adding a static
<script>to the page- no per page configuration should be required
- should not accidentally cause multiple toots to be created
Which gets me the basic spec:
- Configure service with mastodon client application credentials
- Configure blog location
- Domain + pattern match, so that we can include the script in the blog template and it only causes blog posts to be published
- Create
GETEndpoint- expect the origin URL to be passed as a query arg
- determine whether the URL is a handled blog post
- determine whether the toot already exists or needs to be created
- retrieve the post to make sure it actually exists and extract meta-data
- create mastodon post if it does not yet exist as configured user
- return JSON document about the toot
- client is responsible for fetching the appropriate API endpoints to get replies, boosts and likes
This takes care of posting to mastodon at basically publishing time (really on first access of the post). Since we verify the post's existence, making this call during authoring (i.e. mkdocs serve) is inert.
Infrastructure
Since traffic is likely to be sporadic and burst-y, I'm opting to go serverless, in this case AWS Lambda.
I really tried rationalizing authoring this in Scala, but for lambda, the size and execution overhead difference for something this simple just doesn't make sense, so the service is written in python. Because of its simplicity, I also avoided mastodon client libraries, opting for straight requests calls using the mastodon REST API. This is all simple enough that I didn't really want to get a layer of abstraction involved.
The service has minimal state, but we do have to keep the url to mastodon toot_id mapping somewhere. Also, creating that link does bring some complication with it, since we want to guarantee that it happens once and only once. With the design goal of mastodon post generation requiring no manual intervention other than publishing the static site, we are facing a race-condition of that first hit to the page. The operation of checking for the existence and then creating a post is non-atomic. Already having a postgres RDS deployed, I am using it along with some row-level locking semantics to guarantee atomic post creation.
Implementation
Create and authorize the client application
This is done out of band from the service and just once to get the credentials we need to post as the user. ( The below is based on Obtaining client app access )
Next, we can authorize this app to create new statuses on our behalf by accessing the below URL in a browser that is currently logged into our mastodon account (if you are not logged in, it will return a login page). This step could be built into our service as part of an on-boarding API, but for now, the service is a single blog service with static configuration.
Note
I tried just asking for write:statuses on my instance, but that came back as an invalid scope, so I am authorizing for the rather broad write scope.
https://mastodon.example/oauth/authorize?client_id=CLIENT_ID&scope=read+write&redirect_uri=urn:ietf:wg:oauth:2.0:oob&response_type=code
This will result in an HTML page with an authorization code that we can use to obtain an Authorization Token:
You can verify this token with:
And if you go to https://mastodon.example/oauth/authorized_applications, you should see BlogToMastodonService under Authorized Apps.
Running Lambda locally
I understand that this should normally be done with AWS SAM, but I could not get it to play with my local Docker install. Since I'm not trying to do anything beyond a basic HTTP request/response, I put together a simplistic http wrapper around the lambda function signature:
lambda_http_runner.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 | |
Given a python file containing a lambda_handler such as
you start with server with
And every Http request you make to http://localhost:8000/some/path will call the lambda_handler function.
Configuration
This being a single blog service right now, it's entirely configured by environment variables:
MASTODON_HOST- We are assuming that the host will be accessed via
https:// - This is used both for the function to create the toot and returned to the caller to format client UI
- We are assuming that the host will be accessed via
MASTODON_USER- Mastodon user under which the blog posts are created
- This is only used to return to the caller to construct a mastodon link
MASTODON_OAUTH_TOKEN- OAuth Token we created above to let the service post on behalf of the user
BLOG_POST_PATTERN- Regex pattern to identify posts from referer headers
- e.g.
^https://claassen.net/geek/blog/\d+/\d+/[^/]+for this blog
BLOG_POST_POSTFIX- Line to append to every post
- e.g. common hash tags, such as
#blog,#iloggable - The mkdocs for material blog plug-in does not appear to expose tags from front matter as
<meta>tags. Might have to create my own plug-in to expose more front matter into the post header
BLOG_TITLE_PATTERN- Regex pattern to extract
titlefromog:title<meta> - e.g. the mkdocs for material blog plug-in adds the site name to each post's title in
og:title, so I use^(?P<title>.*?)( - claassen\.net|)$to extract just the post title
- Regex pattern to extract
DATABASE_*- standard
USER,HOST,PASSWORD, etc. for configuring the connection to the database
- standard
Determine the blog post
As stated above we're using a url query parameter to determine what post is being looked up. It's up to the client to clean the document.URL of extraneous query and fragments to ensure the canonical post URL.
def get_post_url(event):
url = (event.get('queryStringParameters') or {}).get('url')
if not url:
raise BadRequest("No `url` query argument provided")
if not BLOG_POST_RE.match(url):
raise BadRequest("Provided `url` is not a handled")
logger.debug(f"invoked for {url}")
return url
The reason for BLOG_POST_PATTERN is only for security. The service is wide open, so anyone can call it with any URL and this protects us from toots being generated for unhandled URLs. It is also for the convenience of allowing the code responsible for calling this service to live in a post page template and not have to worry about archive, tag or category versions triggering a new toot.
Of course, unless your blog is brand new, there's still the problem of it creating a post for every old page being accessed. I solved this by using the sitemap to import every existing URL with a toot_id of -1 which the client can ignore. It does mean I can't have discussions on old posts, but I can live with that.
And alternate solution would be to use a dedicated account just for your blog and generating a toot for every existing post and only after doing that, publicly announce the new account. It might still be a nuisance to your instance's local timeline and get you in trouble, so proceed with caution.
Get Or Create Post Record
As mentioned above, since we're lazy triggering the mastodon post on first page access, we have a race condition on that get_or_create_post call. We address it by using postgresql row-level locking as our coordination mechanism.
For now the posts table is really just a mapping from url to post_id.
CREATE TABLE posts (
id bigserial PRIMARY KEY,
toot_id bigint,
url varchar NOT NULL
);
CREATE unique index on posts (url);
Every request coming in, after verifying that the url fits the expected pattern, tries to get the toot_id for the url.
We use FOR SHARE so that this call blocks in case we're currently populating toot_id.
If no match is found, we do a blind insert, so ensure we have a row to lock on:
Now we can try the SELECT again, this time with FOR UPDATE:
In the race condition that multiple requests fail to get a toot_id because it does not exist yet, the first request will acquire the lock, fetch the id and a null toot_id which signifies that it needs to create the mastodon post.
The other requests that hit this call will block on the SELECT, as well as any new requests that try the FOR SHARE SELECT.
Once the first request completes the post and updates the row with the toot_id, it commits its transaction, releasing its lock. At this time the next request that blocked on FOR UPDATE will acquire the lock, but since it now receives a toot_id it will immediately release the lock and return the information.
Putting this together looks like this
def get_toot_id(url):
with get_db_connection() as conn:
cur = conn.cursor(cursor_factory=RealDictCursor)
cur.execute(
"SELECT id, toot_id FROM posts WHERE url = %s FOR SHARE",
(url,)
)
row = cur.fetchone()
toot_id = row.get('toot_id') if row else None
if toot_id:
return toot_id #(1)!
if not row: #(2)!
cur.execute(
"INSERT into posts (url) VALUES(%s) ON CONFLICT DO NOTHING",
(url,)
)
cur.execute(
"SELECT id, toot_id FROM posts WHERE url = %s FOR UPDATE", (url,)
)
row = cur.fetchone()
toot_id = row['toot_id']
if toot_id:
return toot_id #(3)!
post_id = row['id']
toot_id = create_toot(url, post_id)
cur.execute(
"UPDATE posts SET toot_id = %s WHERE id = %s",
(toot_id, post_id)
)
return toot_id #(4)!
rowexists and contains atoot_idrowdid not exist at time of check, but may now, so insert and ignore any errorsrowwas populated withtoot_idwhile we were in line to lock it and retrieve it- we were responsible for creating the
toot_idand updated the lockedrow
Creating the Mastodon post
To create the toot, we fetch the blog post both to validate that it does exist and to extract some meta-data for the toot. Extracting the meta-data is done with a very rudimentary implementation of HTMLParser that only looks for head and meta tags within it and extracts those property names and contents as a dictionary:
class HTMLMetaParser(HTMLParser):
def __init__(self, *args, **kwargs):
self.in_head = False
self.meta = {}
super().__init__(*args, **kwargs)
def handle_starttag(self, tag: str,
attrs: list[tuple[str, Optional[str]]]) -> None:
if self.in_head and tag == 'meta':
prop, content = None, None
for k, v in attrs:
if k == 'property':
prop = v
if k == 'content':
content = v
if prop:
self.meta[prop] = content
elif tag == 'head':
self.in_head = True
def handle_endtag(self, tag: str) -> None:
if self.in_head and tag == 'head':
self.in_head = False
The format of the toot is
where each variable (excepturl) may or may not exist. Since I have the social plug-in for mkdocs for material installed, an image is generated and referenced in the page under og:image and twitter:image, one of which pretty much all mastodon clients will look up and include when rendering the post:
We can safely return a 400 if the page doesn't exist, since the client ignores non-200 responses and the row is discarded because we exited the transaction with block with an exception, triggering a rollback.
def create_toot(url, post_id):
logger.debug(f"creating toot for post_id {post_id}/{url}")
response = requests.get(url)
if response.status_code != 200:
raise BadRequest("Post does not exist yet")
parser = HTMLMetaParser()
parser.feed(response.text)
parser.close()
title = parser.meta.get('og:title')
if title and BLOG_TITLE_RE:
m = BLOG_TITLE_RE.match(title)
if m:
title = m.group('title')
description = parser.meta.get('og:description')
status = ""
if title:
status = f"{title}\n\n"
if description:
status += f"{description}\n"
if BLOG_POST_POSTFIX:
status += f"{BLOG_POST_POSTFIX}\n"
status += url
status_url = f"https://{MASTODON_HOST}/api/v1/statuses"
response = requests.post(
status_url,
headers={"Authorization": f"Bearer {MASTODON_OAUTH_TOKEN}",
"Idempotency-Key": md5(url)},
data=dict(status=status)
)
if response.status_code != 200:
raise Exception(
f"Toot creation via {status_url} failed: "
f"[{response.status_code}] {response.text}"
)
return int(response.json()['id'])
The toot is created with an application/x-www-form-urlencoded POST to /api/v1/statuses using the token we created above. We're also sending an Idempotency-Key to further prevent double-posting. Since we created this post record in our database in a transaction, it should not be possible to double-post, but since url is already a unique key, we might as well send its md5 sum as our Idempotency-Key.
postblog.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 | |
Deployment
To deploy this code in AWS Lambda we need to gather the dependencies that our code has over a base python image,
which ends up being requests (which brings urllib with it) and psycopg2. For something more complicated than a single function, you should probably just create a dedicated image, but for this, we'll just use the layer capability of AWS to load in some libraries. That said, psycopg2 requiring custom binaries, gave me some trouble. If I had built the layer inside of an image, maybe that would have taken care of it, but since I was building it straight on my mac, it ended up with Mac binaries. The solution to this was using aws-psycopg2 instead, which installs the proper binaries and psycopg2.
- Install the dependencies into a directory named
python - Zip up the
pythondirectory. This is the layer package - Go to AWS Lambda - Layers
- Select Create layer
- Name:
postblog-deps - Upload a .zip file
- Really should have uploaded it to S3 first, since this file is 23MB
- Create
Now we can create the function in Lambda.
- Go to AWS Lambda - Functions
- Select Create function
- Select Author from Scratch
- Select python 3.9 as the runtime
- not a hard requirement, just what I used for the my virtualenv, so sticking with it for deployment
- Add trigger
- API Gateway
- Create new API
- REST API
- Security:
Open - Add
- Select Code tab
- Paste contents of
postblog.pyinto thelambda_functioneditor tab - Select Add a layer
- Custom layers
- Select postblog-deps
- Add
- Paste contents of
- Select Configuration tab
- Select Environment variables
- Add all the above defined env vars
- I started with my dev setup, which used a dummy mastodon account and
http://localhost:8001as the blog location. More on that below. - Not a fan of putting secrets in to the UI like this. I'd rather use an env file, but couldn't find an option for that
- Really should just use parameter store. AWS provides a layer to simplify that, but for now I ended up using the env vars in the UI
- Save
- Select RDS databases
- Connect to RDS database
- Select your RDS or create one
- Do not use a database proxy
- AWS warns against this, but this is a low volume function, so i'm risking it. We'll see if that ends up biting me :)
- Create
- Switch to Test tab
- Paste the minimal event our function expects
{ "version": "2.0", "routeKey": "$default", "queryStringParameters": { "url": "http://localhost:8001/geek/blog/2024/02/mastodon-integration.html" }, "isBase64Encoded": false }- This assumes the database already has an event for this URL already in the database, since the lambda cannot validate
http://localhost:8001
- This assumes the database already has an event for this URL already in the database, since the lambda cannot validate
- Click Test
- If this succeeds, we've established that the code "compiles" and can talk to our RDS.
- Paste the minimal event our function expects
At this point, I'd recommend updating the post pattern to the production value, but keep the dummy mastodon account, because we're not out of the woods yet. For me I discovered, that once I tried a real URL, it would always time out. This is where having logger.setLevel("DEBUG") is essential, otherwise your lambda logging won't make it into cloudwatch (it seems to default to ERROR).
Adding a NAT gateway
Since I have to reach my RDS, my lambda function is in my VPC (not sure if that's the default now anyway). That prevented it from accessing the public internet, and thus hung on trying to fetch the blog post (and would have then hung as well accessing the mastodon instance to post).
If you click on the Configuration - VPC tab, you even get a warning about this:
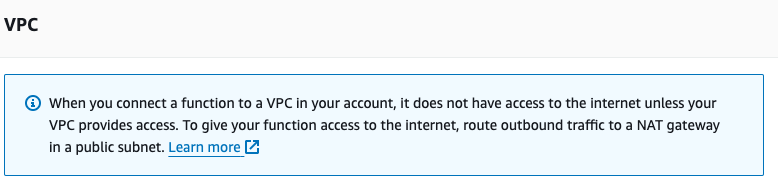
Except the Learn more link leads nowhere ¯\_(ツ)_/¯ I did find "How do I give internet access to a Lambda function that's connected to an Amazon VPC?" which was somewhat helpful, but mostly it led me to read up on more networking concepts to understand and finally solve the problem.
A quick, and probably mostly wrong, explanation for the underlying problem is that in order to talk to hosts on the public IPv4 internet you have to have an IPv4 address yourself. My VPC already has an Internet Gateway, which routes the traffic, but you still need to have a public IP. My EC2 instances were always configured with a public IP, since that's how I ssh'ed into them. Incidentally this is also the reason my fargate services would hang on making requests if iI tried to create them without a public IP. But the lambda does not have a public IP. I mean, it does, since I have an API Gateway, but I guess I don't get to leverage that shared resource for my connections.
The way around the problem of lambda not having a public IP is to create a NAT Gateway (which uses an Elastic IPs) along with some new subnets and a routing table to connect them.
This assumes that your VPC already has an Internet Gateway. If not create one here.
First, we'll create the NAT
- Go to VPC - NAT gateways
- Select Create NAT gateway
- Pick a subnet, really, any subnet
PublicConnectivity Type- Allocate an Elastic IP
Next, we'll create a routing table for this NAT
- Go to VPC - Route tables
- Select Create route table
- Pick your VPC
- Create
- Edit Routes
- Add route
- Destination:
0.0.0.0/0 - Target: NAT Gateway
{the NAT you created above}
- Destination:
Now we'll create two new subnets
- Go to VPC - Subnets
- Select Create subnet
- Pick an IPv4 CIDR range not already used
- I.e. if the highest CIDR used by your existing subnets is
192.168.48.0/20add16to get192.168.64.0/20
- I.e. if the highest CIDR used by your existing subnets is
- Add a second subnet
- Create
- Select each subnet
- Select Route table tab
- Edit route table association
- Pick the route table created above
Finally, we update the lambda to use the new subnets
- Go back to AWS Lambda - Functions
- Select your function
- Select the Configuration tab
- Select VPC
- Edit
- Remove the currently associated subnets
- Add the two newly created subnets
- Save
Now your lambda should be good to go.
The Client
To render the thread, I'm using Daniel's mastodon-comments component. That won't get me likes or boosts, but it's sufficient to get this off the ground. Rather than embedding it directly, I use a bit of javascript to generate the component in response to calling my web service:
document$.subscribe() is a mkdocs for material function for document load. You can use whatever mechanism you prefer if not using mkdocs.
Because we need a canonical URL for the blogpost, we parse document.URL, so that we can strip query args, fragment and possible user/password exposure. Non-200s show up as errors in the console but just result in no comments on the post. And toot_ids of zero or less are ignored (so we can populate the database with exceptions).
The results of the above being called on document load should be visible below under the Comments header.
Where to go from here
As I said, I want to use the toot's likes as the blog post likes and I would also like to show boosts, sort of like track-backs.
Another bit that always bugs me about the mastodon experience is how you follow a link to the origin server and then have to enter your instance's url so that you can follow the post back to your instance before you can reply. I'd like try putting a text box above my comments where you can enter your instance url and it rewrites the links to take you straight to your instance to reply. I'd also like to keep that info in a cookie, so you only have to do it once (for that odd repeat visitor).
Although, all that's really client side work, and so maybe I can get my other projects to pull rank for a bit before getting much deeper into this.